
3. The SD and the Normal Curve¶
We know that the mean is the balance point of the histogram. Unlike the mean, the SD is usually not easy to identify by looking at the histogram.
However, there is one shape of distribution for which the SD is almost as clearly identifiable as the mean. That is the bell-shaped disribution. This section examines that shape, as it appears frequently in probability histograms and also in some histograms of data.
3.1. A Roughly Bell-Shaped Histogram of Data¶
Let us look at the distribution of heights of mothers in our familiar sample of 1,174 mother-newborn pairs. The mothers’ heights have a mean of 64 inches and an SD of 2.5 inches. Unlike the heights of the basketball players, the mothers’ heights are distributed fairly symmetrically about the mean in a bell-shaped curve.
baby = pd.read_csv(path_data + 'baby.csv')
heights = baby['Maternal Height']
mean_height = np.round(np.mean(heights), 1)
mean_height
64.0
sd_height = np.round(np.std(heights), 1)
sd_height
2.5
positions = np.arange(-3, 3.1, 1)*sd_height + mean_height
unit = 'inch'
fig, ax = plt.subplots(figsize=(8,5))
ax.hist(baby['Maternal Height'], bins=np.arange(55.5, 72.5, 1),
density=True,
color='blue',
alpha=0.8,
ec='white',
zorder=5)
y_vals = ax.get_yticks()
y_label = 'Percent per ' + (unit if unit else 'unit')
x_label = 'Maternal Height (' + (unit if unit else 'unit') +')'
ax.set_yticklabels(['{:g}'.format(x * 100) for x in y_vals])
plt.xticks(positions)
plt.ylabel(y_label)
plt.xlabel(x_label)
plt.title('');
plt.show()
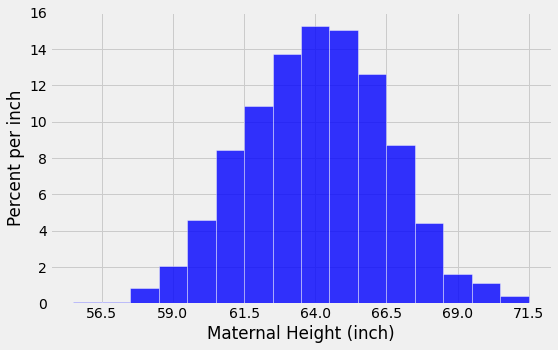
The last two lines of code in the cell above change the labeling of the horizontal axis. Now, the labels correspond to “average \(\pm\) \(z\) SDs” for \(z = 0, \pm 1, \pm 2\), and \(\pm 3\). Because of the shape of the distribution, the “center” has an unambiguous meaning and is clearly visible at 64.
3.1.1. How to Spot the SD on a Bell Shaped Curve¶
To see how the SD is related to the curve, start at the top of the curve and look towards the right. Notice that there is a place where the curve changes from looking like an “upside-down cup” to a “right-way-up cup”; formally, the curve has a point of inflection at which the curve changes from concavity-up to concavity-down depending upon direction of travel on curve. That point is one SD above average. It is the point \(z=1\), which is “average plus 1 SD” = 66.5 inches.
Symmetrically on the left-hand side of the mean, the point of inflection is at \(z=-1\), that is, “average minus 1 SD” = 61.5 inches.
In general, for bell-shaped distributions, the SD is the distance between the mean and the points of inflection on either side.
3.1.2. The standard normal curve¶
All the bell-shaped histograms that we have seen look essentially the same apart from the labels on the axes. Indeed, there is really just one basic curve from which all of these curves can be drawn just by relabeling the axes appropriately.
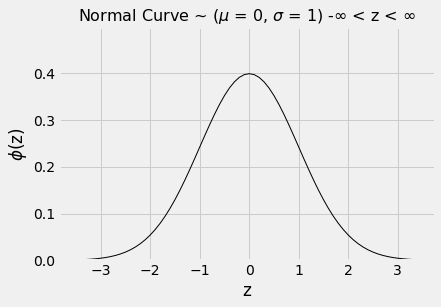
To draw that basic curve, we will use the units into which we can convert every list: standard units. The resulting curve is therefore called the standard normal curve.
The standard normal curve has an impressive equation. But for now, it is best to think of it as a smoothed outline of a histogram of a variable that has been measured in standard units and has a bell-shaped distribution.
The graph below is the output of the function ‘plot_normal_cdf’, this function utilises the probability density function pdf method of the stats function from the scipy module.
plot_normal_cdf()
3.1.3. ‘Mechanics’ behind the function¶
For your interest
#pdf - probability density function
#cdf - cumulative distribution function
#ppf - percent point function (inverse of CDF)
from scipy.stats import norm
fig, ax = plt.subplots(1, 1)
#calculate a few first moments
mean, var, skew, kurt = norm.stats(moments='mvsk')
#display the pdf
x = np.linspace(norm.ppf(0.01), norm.ppf(0.99), 100)
ax.plot(x, norm.pdf(x), 'r-', lw=5, alpha=0.6, label='norm pdf')
ax.legend(loc='best', frameon=False)
rv = norm()
ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf')
#Check accuracy of cdf and ppf:
vals = norm.ppf([0.001, 0.5, 0.999])
np.allclose([0.001, 0.5, 0.999], norm.cdf(vals))
#Generate random numbers:
r = norm.rvs(size=1000)
#Compare the histogram:
ax.hist(r, density=True, histtype='stepfilled', alpha=0.2)
ax.legend(bbox_to_anchor=(1.04,1), loc="upper left", frameon=False)
plt.show()
As always when you examine a new histogram, start by looking at the horizontal axis. On the horizontal axis of the standard normal curve, the values are standard units.
Here are some properties of the curve. Some are apparent by observation, and others require a considerable amount of mathematics to establish.
The total area under the curve is 1. So you can think of it as a histogram drawn to the density scale.
The curve is symmetric about 0. So if a variable has this distribution, its mean and median are both 0.
The points of inflection of the curve are at -1 and +1.
If a variable has this distribution, its SD is 1. The normal curve is one of the very few distributions that has an SD so clearly identifiable on the histogram.
Since we are thinking of the curve as a smoothed histogram, we will want to represent proportions of the total amount of data by areas under the curve.
Areas under smooth curves are often found by calculus, using a method called integration. It is a fact of mathematics, however, that the standard normal curve cannot be integrated in any of the usual ways of calculus.
Therefore, areas under the curve have to be approximated. That is why almost all statistics textbooks carry tables of areas under the normal curve. It is also why all statistical systems, including a module of Python, include methods that provide excellent approximations to those areas.
from scipy import stats
3.1.4. The standard normal “cdf”¶
The fundamental function for finding areas under the normal curve is stats.norm.cdf. It takes a numerical argument and returns all the area under the curve to the left of that number. Formally, it is called the “cumulative distribution function” of the standard normal curve. That rather unwieldy mouthful is abbreviated as cdf.
Let us use this function to find the area to the left of \(z=1\) under the standard normal curve.
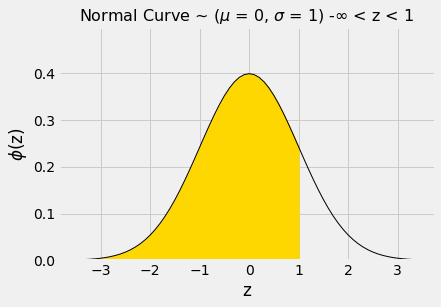
The numerical value of the shaded area can be found by calling stats.norm.cdf.
stats.norm.cdf(1)
0.8413447460685429
That’s about 84%. We can now use the symmetry of the curve and the fact that the total area under the curve is 1 to find other areas.
The area to the right of \(z=1\) is about 100% - 84% = 16%.
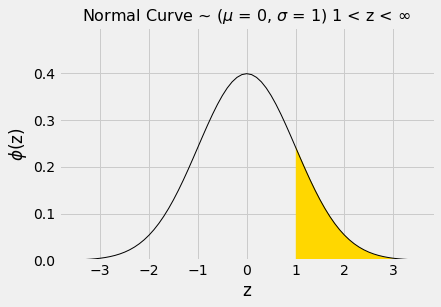
1 - stats.norm.cdf(1)
0.15865525393145707
Or we pass the negative equivalent value
stats.norm.cdf(-1)
0.15865525393145707
The area between \(z=-1\) and \(z=1\) can be computed in several different ways. It is the gold area under the curve below.
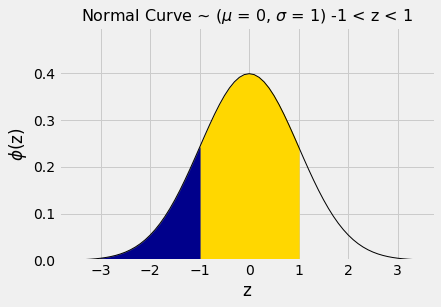
For example, we could calculate the area as “100% - two equal tails”, which works out to roughly 100% - 2x16% = 68%.
Or we could note that the area between \(z=1\) and \(z=-1\) is equal to all the area to the left of \(z=1\), minus all the area to the left of \(z=-1\).
stats.norm.cdf(1) - stats.norm.cdf(-1)
0.6826894921370859
By a similar calculation, we see that the area between \(-2\) and 2 is about 95%.
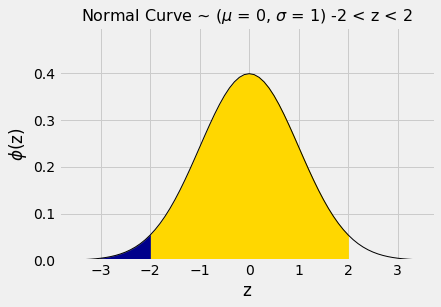
stats.norm.cdf(2) - stats.norm.cdf(-2)
0.9544997361036416
In other words, if a histogram is roughly bell shaped, the proportion of data in the range “average \(\pm\) 2 SDs” is about 95%.
That is quite a bit more than Chebychev’s lower bound of 75%. Chebychev’s bound is weaker because it has to work for all distributions. If we know that a distribution is normal, we have good approximations to the proportions, not just bounds.
The table below compares what we know about all distributions and about normal distributions. Notice that when \(z=1\), Chebychev’s bound is correct but not illuminating.
| Percent in Range | All Distributions: Bound | Normal Distribution: Approximation | | :————— | :—————- –| :——————-| |average \(\pm\) 1 SD | at least 0% | about 68% | |average \(\pm\) 2 SDs | at least 75% | about 95% | |average \(\pm\) 3 SDs | at least 88.888…% | about 99.73% |