
7. Visualization¶
Tables are a powerful way of organizing and visualizing data. However, large tables of numbers can be difficult to interpret, no matter how organized they are. Sometimes it is much easier to interpret graphs than numbers.
In this chapter we will develop some of the fundamental graphical methods of data analysis. Our source of data is the Internet Movie Database, an online database that contains information about movies, television shows, video games, and so on. The site Box Office Mojo provides many summaries of IMDB data, some of which we have adapted. We have also used data summaries from The Numbers, a site with a tagline that says it is “where data and the movie business meet.”
Scatter Plots and Line Graphs¶
The table actors contains data on Hollywood actors, both male and female. The columns are:
** Column ** |
Contents |
|---|---|
|
Name of actor |
|
Total gross domestic box office receipt, in millions of dollars, of all of the actor’s movies |
|
The number of movies the actor has been in |
|
Total gross divided by number of movies |
|
The highest grossing movie the actor has been in |
|
Gross domestic box office receipt, in millions of dollars, of the actor’s |
In the calculation of the gross receipt, the data tabulators did not include movies where an actor had a cameo role or a speaking role that did not involve much screen time.
The table has 50 rows, corresponding to the 50 top grossing actors. The table is already sorted by Total Gross, so it is easy to see that Harrison Ford is the highest grossing actor. In total, his movies have brought in more money at domestic box office than the movies of any other actor.
actors = pd.read_csv(path_data + 'actors.csv')
actors.head()
| Actor | Total Gross | Number of Movies | Average per Movie | #1 Movie | Gross | |
|---|---|---|---|---|---|---|
| 0 | Harrison Ford | 4871.7 | 41 | 118.8 | Star Wars: The Force Awakens | 936.7 |
| 1 | Samuel L. Jackson | 4772.8 | 69 | 69.2 | The Avengers | 623.4 |
| 2 | Morgan Freeman | 4468.3 | 61 | 73.3 | The Dark Knight | 534.9 |
| 3 | Tom Hanks | 4340.8 | 44 | 98.7 | Toy Story 3 | 415.0 |
| 4 | Robert Downey, Jr. | 3947.3 | 53 | 74.5 | The Avengers | 623.4 |
Terminology. A variable is a formal name for what we have been calling a “feature”, such as ‘number of movies.’ The term variable emphasizes that the feature can have different values for different individuals – the numbers of movies that actors have been in varies across all the actors.
Variables that have numerical values, such as ‘number of movies’ or ‘average gross receipts per movie’ are called quantitative or numerical variables.
Scatter Plots¶
A scatter plot displays the relation between two numerical variables. You saw an example of a scatter plot in an early section where we looked at the number of periods and number of characters in two classic novels.
The matplotlib method scatter draws a scatter plot consisting of one point for each row of the DataFrame. Its first argument is the label of the column to be plotted on the horizontal axis, and its second argument is the label of the column on the vertical.
matplotlib style Restart and clear kernel to apply. To get an idea of the effect of style uncomment (remove the hash symbol) the instruction #plots.style.use('fivethirtyeight')
and comment plots.style.use('bmh') in the first cell of this notebook (import cell).
matplotlib scatter plot¶
x = actors['Number of Movies']
y = actors['Total Gross']
fig, ax = plt.subplots()
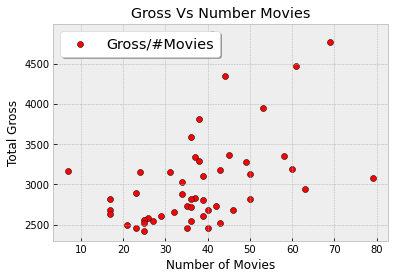
ax.scatter(x, y, c='red', label='Gross/#Movies', edgecolors='black')
ax.set_title('Gross Vs Number Movies')
ax.set_xlabel('Number of Movies')
ax.set_ylabel('Total Gross')
legend = ax.legend(loc='upper left', shadow=True, fontsize='x-large')
# Put a nicer background color on the legend.
legend.get_frame().set_facecolor('white')
plt.show()
Pandas scatter plot¶
actors.plot.scatter(x = 'Number of Movies', y = 'Total Gross', c='red', label='Gross Vs Number Movies')
plt.show()
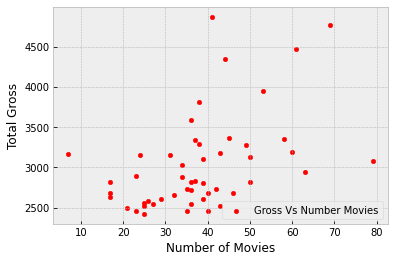
The plot contains 50 points, one point for each actor in the table. You can see that it slopes upwards, in general. The more movies an actor has been in, the more the total gross of all of those movies – in general.
Formally, we say that the plot shows an association between the variables, and that the association is positive: high values of one variable tend to be associated with high values of the other, and low values of one with low values of the other, in general.
Of course there is some variability. Some actors have high numbers of movies but middling total gross receipts. Others have middling numbers of movies but high receipts. That the association is positive is simply a statement about the broad general trend.
Later in the course we will study how to quantify association. For the moment, we will just think about it qualitatively.
Now that we have explored how the number of movies is related to the total gross receipt, let’s turn our attention to how it is related to the average gross receipt per movie.
x = actors['Number of Movies']
y = actors['Average per Movie']
plt.scatter(x, y, c='blue')
plt.title('Gross Vs Avg per Movie')
plt.xlabel('Number of Movies')
plt.ylabel('Average per Movie')
plt.show()
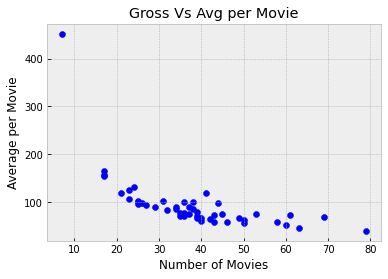
This is a markedly different picture and shows a negative association. In general, the more movies an actor has been in, the less the average receipt per movie.
Also, one of the points is quite high and off to the left of the plot. It corresponds to one actor who has a low number of movies and high average per movie. This point is an outlier. It lies outside the general range of the data. Indeed, it is quite far from all the other points in the plot.
We will examine the negative association further by looking at points at the right and left ends of the plot.
For the right end, let’s zoom in on the main body of the plot by just looking at the portion that doesn’t have the outlier.
no_outlier = actors[actors['Number of Movies'] > 10]
no_outlier.plot.scatter('Number of Movies', 'Average per Movie') #N.B. a pandas scatterplot
plt.show()
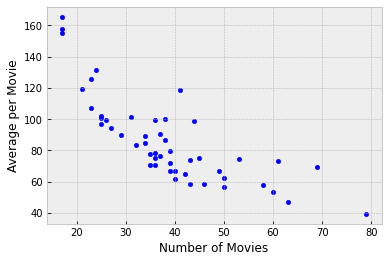
The negative association is still clearly visible. Let’s identify the actors corresponding to the points that lie on the right hand side of the plot where the number of movies is large:
actors[actors['Number of Movies'] > 60]
| Actor | Total Gross | Number of Movies | Average per Movie | #1 Movie | Gross | |
|---|---|---|---|---|---|---|
| 1 | Samuel L. Jackson | 4772.8 | 69 | 69.2 | The Avengers | 623.4 |
| 2 | Morgan Freeman | 4468.3 | 61 | 73.3 | The Dark Knight | 534.9 |
| 19 | Robert DeNiro | 3081.3 | 79 | 39.0 | Meet the Fockers | 279.3 |
| 21 | Liam Neeson | 2942.7 | 63 | 46.7 | The Phantom Menace | 474.5 |
The actor Robert DeNiro has the highest number of movies and the lowest average receipt per movie. Other actors are at points that are not very far away, but DeNiro’s is at the extreme end.
To understand the negative association, note that the more movies an actor is in, the more variable those movies might be, in terms of style, genre, and box office draw. For example, an actor might be in some high-grossing action movies or comedies (such as Meet the Fockers), and also in a large number of smaller films that may be excellent but don’t draw large crowds. Thus the actor’s value of average receipts per movie might be relatively low.
To approach this argument from a different direction, let us now take a look at the outlier.
actors[actors['Number of Movies'] < 10]
| Actor | Total Gross | Number of Movies | Average per Movie | #1 Movie | Gross | |
|---|---|---|---|---|---|---|
| 14 | Anthony Daniels | 3162.9 | 7 | 451.8 | Star Wars: The Force Awakens | 936.7 |
As an actor, Anthony Daniels might not have the stature of Robert DeNiro. But his 7 movies had an astonishingly high average receipt of nearly \(452\) million dollars per movie.
What were these movies? You might know about the droid C-3PO in Star Wars:
 That’s Anthony Daniels inside the metallic suit. He plays C-3PO.
That’s Anthony Daniels inside the metallic suit. He plays C-3PO.
Mr. Daniels’ entire filmography (apart from cameos) consists of movies in the high-grossing Star Wars franchise. That explains both his high average receipt and his low number of movies.
Variables such as genre and production budget have an effect on the association between the number of movies and the average receipt per movie. This example is a reminder that studying the association between two variables often involves understanding other related variables as well.
Line Graphs¶
Line graphs are among the most common visualizations and are often used to study chronological trends and patterns.
The table movies_by_year contains data on movies produced by U.S. studios in each of the years 1980 through 2015. The columns are:
Column |
Content |
|---|---|
|
Year |
|
Total domestic box office gross, in millions of dollars, of all movies released |
|
Number of movies released |
|
Highest grossing movie |
movies_by_year = pd.read_csv(path_data + 'movies_by_year.csv')
movies_by_year.head(10)
| Year | Total Gross | Number of Movies | #1 Movie | |
|---|---|---|---|---|
| 0 | 2015 | 11128.5 | 702 | Star Wars: The Force Awakens |
| 1 | 2014 | 10360.8 | 702 | American Sniper |
| 2 | 2013 | 10923.6 | 688 | Catching Fire |
| 3 | 2012 | 10837.4 | 667 | The Avengers |
| 4 | 2011 | 10174.3 | 602 | Harry Potter / Deathly Hallows (P2) |
| 5 | 2010 | 10565.6 | 536 | Toy Story 3 |
| 6 | 2009 | 10595.5 | 521 | Avatar |
| 7 | 2008 | 9630.7 | 608 | The Dark Knight |
| 8 | 2007 | 9663.8 | 631 | Spider-Man 3 |
| 9 | 2006 | 9209.5 | 608 | Dead Man's Chest |
The Table method plot produces a line graph. Its two arguments are the same as those for scatter: first the column on the horizontal axis, then the column on the vertical. Here is a line graph of the number of movies released each year over the years 1980 through 2015.
#N.B. this is a Pandas plot
movies_by_year.plot('Year', 'Number of Movies')
plt.show()

The graph rises sharply and then has a gentle upwards trend though the numbers vary noticeably from year to year. The sharp rise in the early 1980’s is due in part to studios returning to the forefront of movie production after some years of filmmaker driven movies in the 1970’s.
Our focus will be on more recent years. In keeping with the theme of movies, the table of rows corresponding to the years 2000 through 2015 have been assigned to the name century_21.
century_21 = movies_by_year[movies_by_year['Year'] > 1999]
century_21.plot('Year', 'Number of Movies')
plt.show()
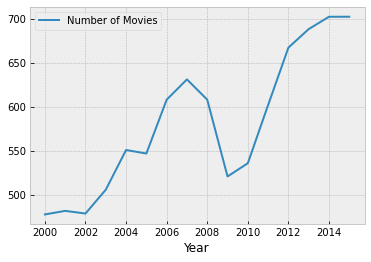
The global financial crisis of 2008 has a visible effect – in 2009 there is a sharp drop in the number of movies released.
The dollar figures, however, didn’t suffer much.
century_21.plot('Year', 'Total Gross')
plt.show()
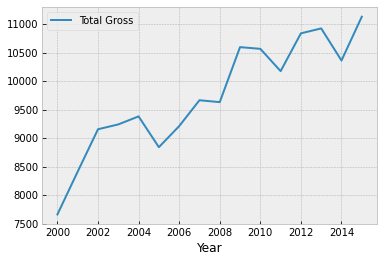
The total domestic gross receipt was higher in 2009 than in 2008, even though there was a financial crisis and a much smaller number of movies were released.
One reason for this apparent contradiction is that people tend to go to the movies when there is a recession. “In Downturn, Americans Flock to the Movies,” said the New York Times in February 2009. The article quotes Martin Kaplan of the University of Southern California saying, “People want to forget their troubles, and they want to be with other people.” When holidays and expensive treats are unaffordable, movies provide welcome entertainment and relief.
In 2009, another reason for high box office receipts was the movie Avatar and its 3D release. Not only was Avatar the #1 movie of 2009, it is also by some calculations the second highest grossing movie of all time, as we will see later.
century_21[century_21['Year'] == 2009]
| Year | Total Gross | Number of Movies | #1 Movie | |
|---|---|---|---|---|
| 6 | 2009 | 10595.5 | 521 | Avatar |